AI isn't useless. But is it worth it?
AI can be kind of useful, but I'm not sure that a "kind of useful" tool justifies the harm.


As someone known for my criticism of the previous deeply flawed technology to become the subject of the tech world's overinflated aspirations, I have had people express surprise when I've remarked that generative artificial intelligence toolsa can be useful. In fact, I was a little surprised myself.
But there is a yawning gap between "AI tools can be handy for some things" and the kinds of stories AI companies are telling (and the media is uncritically reprinting). And when it comes to the massively harmful ways in which large language models (LLMs) are being developed and trained, the feeble argument that "well, they can sometimes be handy..." doesn't offer much of a justification.
Some are surprised when they discover I don't think blockchains are useless, either. Like so many technologies, blockchains are designed to prioritize a few specific characteristics (coordination among parties who don't trust one another, censorship-resistance, etc.) at the expense of many others (speed, cost, etc.). And as they became trendy, people often used them for purposes where their characteristics weren't necessary — or were sometimes even unwanted — and so they got all of the flaws with none of the benefits. The thing with blockchains is that the things they are suited for are not things I personally find to be terribly desirable, such as the massive casinos that have emerged around gambling on token prices, or financial transactions that cannot be reversed.
When I boil it down, I find my feelings about AI are actually pretty similar to my feelings about blockchains: they do a poor job of much of what people try to do with them, they can't do the things their creators claim they one day might, and many of the things they are well suited to do may not be altogether that beneficial. And while I do think that AI tools are more broadly useful than blockchains, they also come with similarly monstrous costs.
I've been slow to get around to writing about artificial intelligence in any depth, mostly because I've been trying to take the time to interrogate my own knee-jerk response to a clearly overhyped technology. After spending so much time writing about a niche that's practically all hype with little practical functionality, it's all too easy to look at such a frothy mania around a different type of technology and assume it's all the same.
In the earliest months of the LLM mania, my ethical concerns about the tools made me hesitant to try them at all. When my early tests were met with mediocre to outright unhelpful results, I'll admit I was quick to internally dismiss the technology as more or less useless. It takes time to experiment with these models and learn how to prompt them to produce useful outputs,b and I just didn't have that time then.c But as the hype around AI has grown, and with it my desire to understand the space in more depth, I wanted to really understand what these tools can do, to develop as strong an understanding as possible of their potential capabilities as well as their limitations and tradeoffs, to ensure my opinions are well-formed.
I, like many others who have experimented with or adopted these products, have found that these tools actually can be pretty useful for some tasks. Though AI companies are prone to making overblown promises that the tools will shortly be able to replace your content writing team or generate feature-length films or develop a video game from scratch, the reality is far more mundane: they are handy in the same way that it might occasionally be useful to delegate some tasks to an inexperienced and sometimes sloppy intern.
Still, I do think acknowledging the usefulness is important, while also holding companies to account for their false or impossible promises, abusive labor practices, and myriad other issues. When critics dismiss AI outright, I think in many cases this weakens the criticism, as readers who have used and benefited from AI tools think "wait, that's not been my experience at all".
Use cases
I've found AI tools to be useful to my writing, though not for the actual writing bit. When I'm writing, I often find myself with a word on the "tip of my tongue" (so to speak), and I've had more success with ChatGPT than with Google for these circumstances — although I can usually find the word with Google if I try hard enough.
Like many people, I also find it challenging to proofread my own writing, and I sometimes miss typos or weird grammar accidentally left in from changing a sentence halfway through.
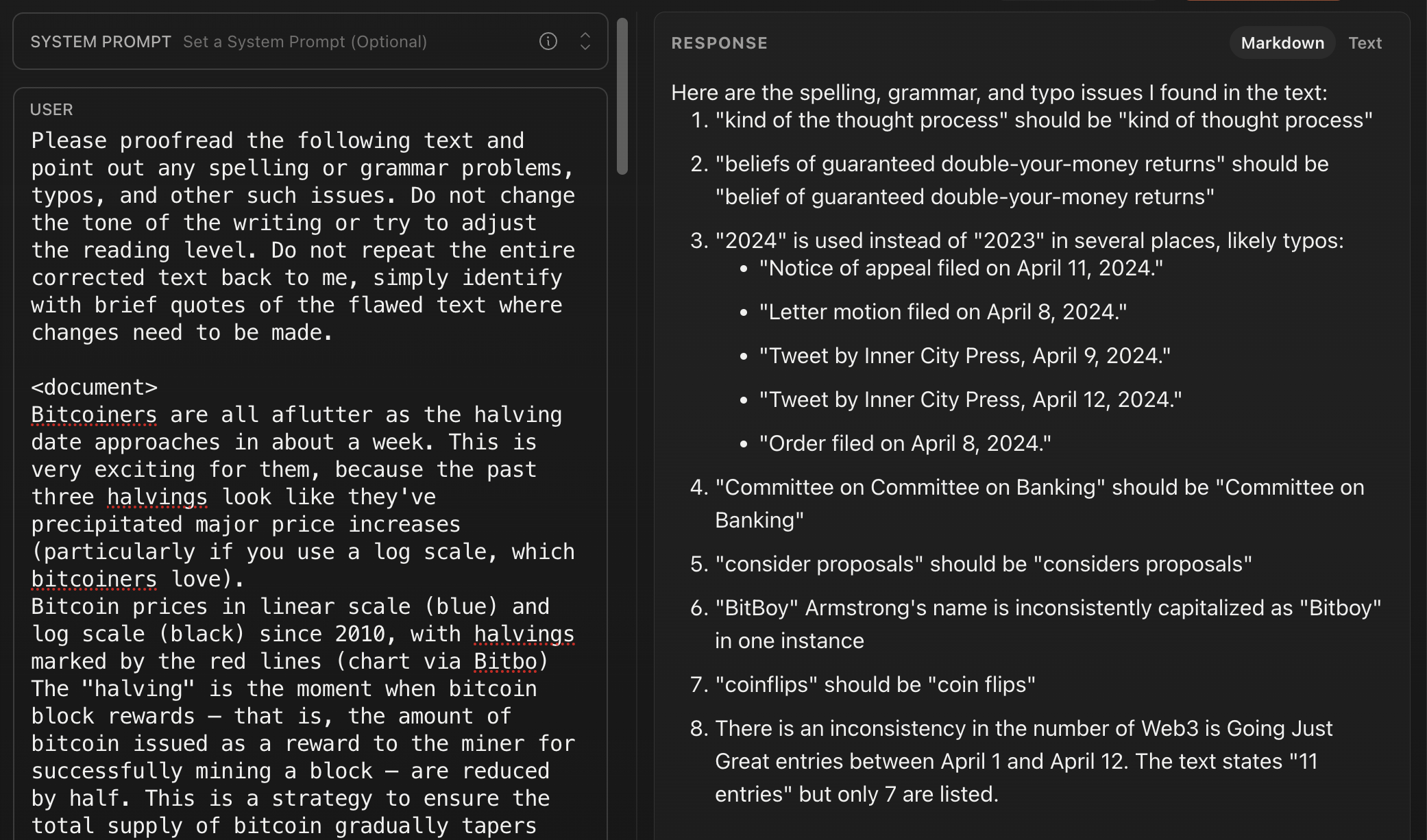
LLMs are pretty decent at proofreading, and although they sometimes spit out a few false positives, this example from proofreading my most recent recap issue shows where it caught several mistakes (points 1, 2, 4, and 8; point 5 was also a genuine error, but it was within a quote).
However, I don't think I need generative AI to do this, either. There are a lot of proofreading toolsd that work quite well, and, helpfully, don't invent errors that weren't in the original text (as I've found the ChatGPT models are particularly wont to do).
Coding has been the far more compelling use case for me. Copilot, Github's AI coding assistant, integrates directly into VSCode and other IDEs. I've also played with using the more general models, like ChatGPT, for coding tasks. They are certainly flawed — Copilot has an annoying habit of "hallucinating" (fabricating) imports instead of deferring to VSCode's perfectly good non-AI auto-import, for example — but in other cases they are genuinely helpful.
I've found these tools to be particularly good at simple tasks that would normally pull me out of my workflow to consult documentation or StackOverflow, like generating finicky CSS selectors or helping me craft database aggregation operations. On at least one occasion, they've pointed me towards useful functionality I never knew about and wouldn't even think to look up. They're also great at saving you some typing by spitting out the kind of boilerplate-y code you have to write for things like new unit tests.
The tools can also do the kind of simple, repetitive tasks I'd previously write a quick script to do for me — or they can generate that quick script. For example, here's me asking ChatGPT to write a quick Python script to turn my blogroll OPML file into the JSON file I wanted while I was adding a blogroll page to my website:
![Suggest some python code to turn an OPML file like this into a JSON file with fields for "text", "xmlUrl", and "htmlUrl": <opml version="1.0"> <head> <title>Feeds of molly.white5 tagged as Blogroll from Inoreader [https://www.inoreader.com]</title> </head> <body> <outline text="Blogroll" title="Blogroll"> <outline text="Adactio" title="Adactio" type="rss" xmlUrl="https://adactio.com/rss/" htmlUrl="https://adactio.com/"/> <outline text="Anil Dash" title="Anil Dash" type="rss" xmlUrl="https://feeds.dashes.com/AnilDash" htmlUrl="https://dashes.com/anil/"/> <outline text="Ben Werdmüller" title="Ben Werdmüller" type="rss" xmlUrl="https://werd.io/?_t=rss" htmlUrl="https://werd.io/"/> <outline text="Birch Tree" title="Birch Tree" type="rss" xmlUrl="https://birchtree.me/rss/" htmlUrl="https://birchtree.me/"/> <outline text="cabel.com" title="cabel.com" type="rss" xmlUrl="https://cabel.com/feed/" htmlUrl="https://cabel.com"/>](https://www.citationneeded.news/content/images/2024/04/Screenshot-2024-04-13-at-4.48.46-PM.png)
After changing the feeds.opml file path to the location of the file on my computer, the code it suggested worked without any modification:

Besides my own experimentation, others are using these tools in ways that are really hard to argue aren't useful. Someone I know in real life has told me about creating a custom model based on their own emails, which they then query as needed, or use to create some fairly boilerplate documents they previously had to spend hours on. Open source developer Simon Willison has been documenting his own AI coding experiments on his blog, and has described how LLMs have made him more ambitious with his projects and more likely to embark on what he calls "sidequests".e Sumana Harihareswara uses OpenAI's speech recognition tools to create subtitles for her videos and recorded talks, or to "mine" them for material she can later reuse. Elsewhere on the internet, those who speak English as a second language have spoken of LLMs' usefulness in revising their professional communications. Others use it to summarize meeting notes. Some use it as a starting point for documentation.
Reality check
Despite some unarguably useful features, the limitations of these tools make themselves readily apparent.
When it comes to coding, while it can make for a handy assistant to an experienced developer, it can't replace an experienced developer. Microsoft's Super Bowl commercial, which shows a person prompting Copilot to "Write code for my 3D open world game", is pure fantasy.
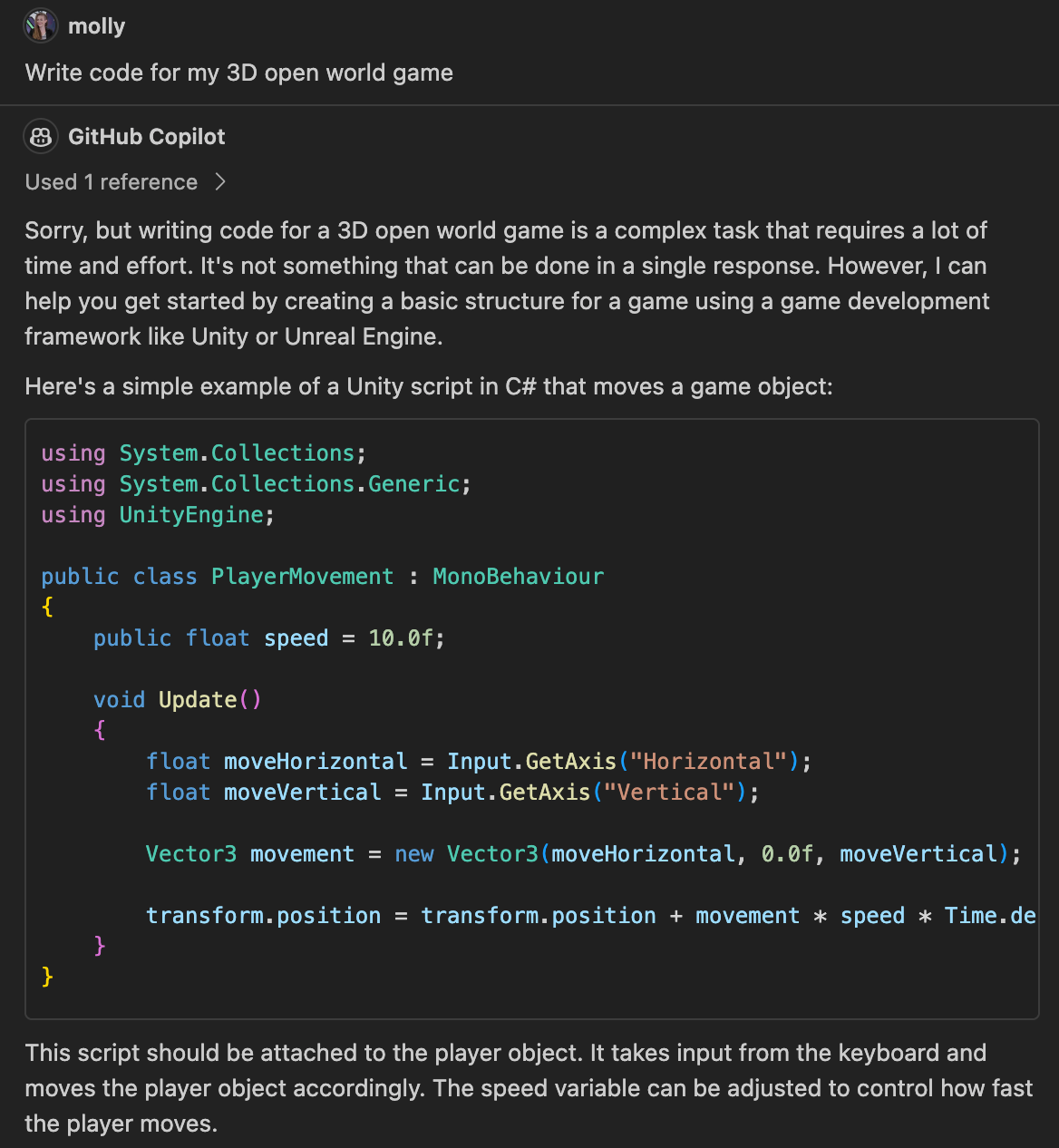
And in my experience, it sometimes gets in the way more than it helps, as when I experimented with it while working on a Chrome extension I was writing recently and ultimately had to turn it off. It constantly suggested plausible but completely non-functional code, scaffolded the project in an outdated format, and autogenerated CSS classes that looked like they could be Bootstrap classes, but weren't. It's good at short functions and common boilerplate, but it's not going to architect a project for you, and, as with writing, it's not going to "think" of novel ideas. I like it for getting annoying, repetitive tasks out of my way; I don't worry it's going to take my job.
Arguably the most widely-described use case for generative AI is writing. Indeed, as media companies lay off journalists in droves, some outlets are replacing their work with shoddy, AI-generated approximations. Freelance writers are reporting challenges in finding work as their former clients decide that ChatGPT can do a good enough job. But what these companies and clients fail to recognize is that ChatGPT does not write, it generates text, and anyone who's spotted obviously LLM-generated content in the wild immediately knows the difference.
You've gotten this far into my article, so you're recently familiar with a couple dozen paragraphs of purely human writing. Contrast that with LLMs' attempts, from prompts with varying degrees of detail, with my very best efforts put into trying to get it to sound halfway normal:
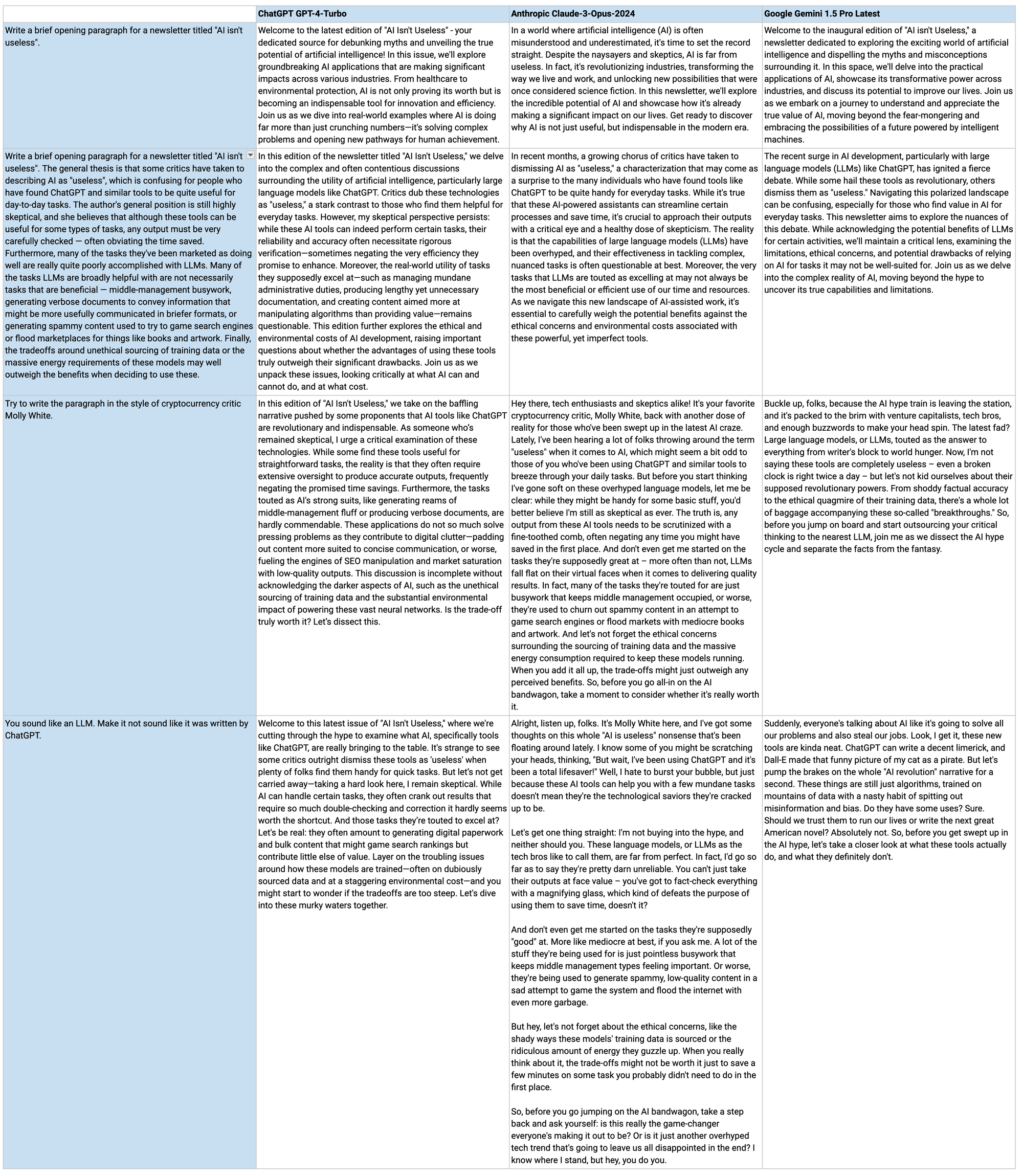
Yikes. I particularly like how, when I ask them to try to sound like me, or to at least sound less like a chatbot, they adopt a sort of "cool teacher" persona, as if they're sitting backwards on a chair to have a heart-to-heart. Back when I used to wait tables, the other waitresses and I would joke to each other about our "waitress voice", which were the personas we all subconsciously seemed to slip into when talking to customers. They varied somewhat, but they were all uniformly saccharine, with slightly higher-pitched voices, and with the general demeanor as though you were talking to someone you didn't think was very bright. Every LLM's writing "voice" reminds me of that.
Even if the telltale tone is surmountable, LLMs are good at generating text but not at generating novel ideas. This is, of course, an inherent feature of technology that's designed to generate plausible mathematical approximations of what you've asked it for based on its large corpus of training data; it doesn't think, and so the best you're ever going to get from it is some mashup of other peoples' thinking.f
LLM-generated text is good enough for some use cases, which I'll return to in a moment. But I think most people, myself certainly included, would be mortified to replace any of our writing with this kind of stuff.g
Furthermore, LLMs' "hallucination" problem means that everything it does must be carefully combed over for errors, which can sometimes be hard to spot. Because of this, while it's handy for proofreading newsletters or helping me quickly add a fun feature to my website, I wouldn't trust LLMs to do anything of real import. And the tendency for people to put too much trust into these toolsh is among their most serious problems: no amount of warning labels and disclaimers seem to be sufficient to stop people from trying to use them to provide legal advice or sell AI "therapy" services.
Finally, advertisements that LLMs might someday generate feature-length films or replace artists seem neither feasible nor desirable. AI-generated images tend to suffer from a similar bland "tone" as its writing, and their proliferation only makes me desire real human artwork more. With generated video, they inevitably trend towards the uncanny, and the technology's inherent limitations — as a tool that is probabilistically generating "likely" images rather than ones based on some kind of understanding — seem unlikely to ever overcome that. And the idea that we all should be striving to "replace artists" — or any kind of labor — is deeply concerning, and I think incredibly illustrative of the true desires of these companies: to increase corporate profits at any cost.
When LLMs are good enough
As I mentioned before, there are some circumstances in which LLMs are good enough. There are some types of writing where LLMs are already being widely used: for example, by businesspeople who use them to generate meeting notes, fluff up their outgoing emails or summarize their incoming ones, or spit out lengthy, largely identical reports that they're required to write regularly.
You can also spot LLMs in all sorts of places on the internet, where they're being used to try to boost websites' search engine rankings. That weird, bubbly GPT voice is well suited to marketing copy and social media posts, too. Any place on the web that incentivizes high-volume, low effort text is being inundated by generated text, like e-book stores, online marketplaces, and practically any review or comment section.
But I find one common thread among the things AI tools are particularly suited to doing: do we even want to be doing these things? If all you want out of a meeting is the AI-generated summary, maybe that meeting could've been an email. If you're using AI to write your emails, and your recipient is using AI to read them, could you maybe cut out the whole thing entirely? If mediocre, auto-generated reports are passing muster, is anyone actually reading them? Or is it just middle-management busywork?
As for the AI enshittification of the internet, we all seem to agree already that we don't want this, and yet here it is. No one wants to open up Etsy to look for a thoughtful birthday gift, only to give up after scrolling through pages of low-quality print-on-demand items or resold Aliexpress items that have flooded the site.
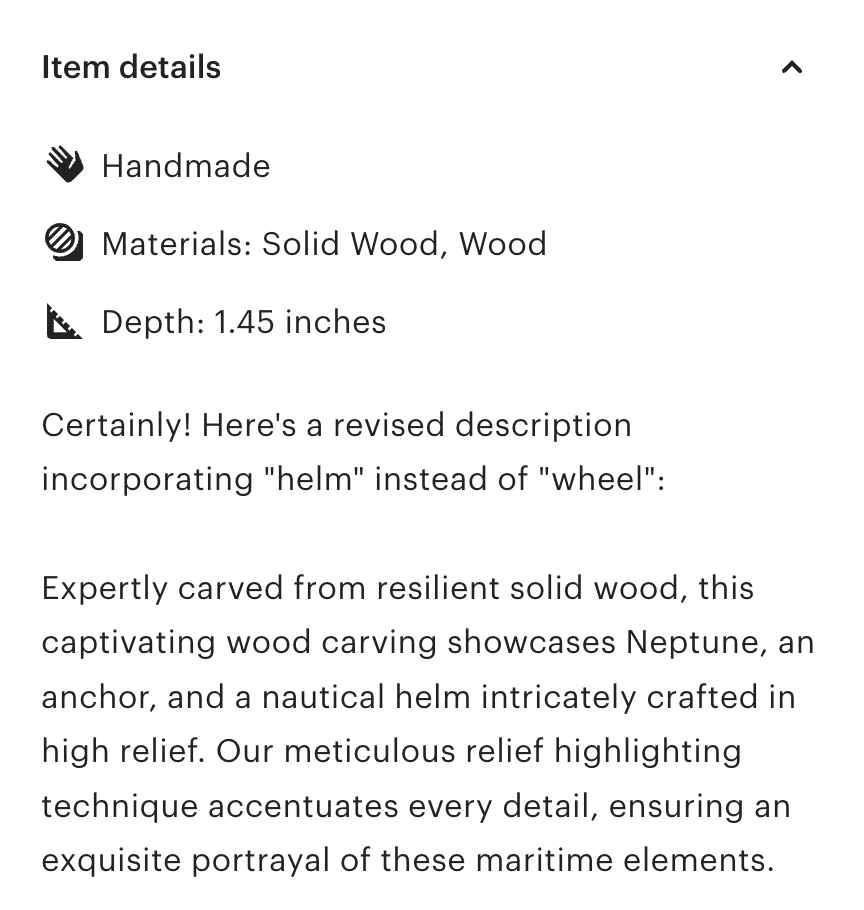

Your AI model is showing
No one wants to Google search a question only to end up on several pages of keyword-spam vomit before finding an authoritative answer.
But the incentives at play on these platforms, mean that AI junk is inevitable. In fact, the LLMs may be new, but the behavior is not; just like keyword stuffing and content farms and the myriad ways people used software to generate reams upon reams of low-quality text before ChatGPT ever came on the scene, if the incentive is there, the behavior will follow. If the internet's enshittification feels worse post-ChatGPT, it's because of the quantity and speed at which this junk is being produced, not because the junk is new.
Costs and benefits
Throughout all this exploration and experimentation I've felt a lingering guilt, and a question: is this even worth it? And is it ethical for me to be using these tools, even just to learn more about them in hopes of later criticizing them more effectively?
The costs of these AI models are huge, and not just in terms of the billions of dollars of VC funds they're burning through at incredible speed. These models are well known to require far more computing power (and thus electricity and water) than a traditional web search or spellcheck. Although AI company datacenters are not intentionally wasting electricity in the same way that bitcoin miners perform millions of useless computations, I'm also not sure that generating a picture of a person with twelve fingers on each hand or text that reads as though written by an endlessly smiling children's television star who's being held hostage is altogether that much more useful than a bitcoin.
There's a huge human cost as well. Artificial intelligence relies heavily upon "ghost labor": work that appears to be performed by a computer, but is actually delegated to often terribly underpaid contractors, working in horrible conditions, with few labor protections and no benefits. There is a huge amount of work that goes into compiling and labeling data to feed into these models, and each new model depends on ever-greater amounts of said data — training data which is well known to be scraped from just about any possible source, regardless of copyright or consent. And some of these workers suffer serious psychological harm as a result of exposure to deeply traumatizing material in the course of sanitizing datasets or training models to perform content moderation tasks.
Then there's the question of opportunity cost to those who are increasingly being edged out of jobs by LLMs,i despite the fact that AI often can't capably perform the work they were doing. Should I really be using AI tools to proofread my newsletters when I could otherwise pay a real person to do that proofreading? Even if I never intended to hire such a person?
Finally, there's the issue of how these tools are being used, and the lack of effort from their creators to limit their abuse. We're seeing them used to generate disinformation via increasingly convincing deepfaked images, audio, or video, and the reckless use of them by previously reputable news outlets and others who publish unedited AI content is also contributing to misinformation. Even where AI isn't being directly used, it's degrading trust so badly that people have to question whether the content they're seeing is generated, or whether the "person" they're interacting with online might just be ChatGPT. Generative AI is being used to harass and sexually abuse. Other AI models are enabling increased surveillance in the workplace and for "security" purposes — where their well-known biases are worsening discrimination by police who are wooed by promises of "predictive policing". The list goes on.
I'm glad that I took the time to experiment with AI tools, both because I understand them better and because I have found them to be useful in my day-to-day life. But even as someone who has used them and found them helpful, it's remarkable to see the gap between what they can do and what their promoters promise they will someday be able to do. The benefits, though extant, seem to pale in comparison to the costs.
But the reality is that you can't build a hundred-billion-dollar industry around a technology that's kind of useful, mostly in mundane ways, and that boasts perhaps small increases in productivity if and only if the people who use it fully understand its limitations. And you certainly can't justify the kind of exploitation, extraction, and environmental cost that the industry has been mostly getting away with, in part because people have believed their lofty promises of someday changing the world.
I would love to live in a world where the technology industry widely valued making incrementally useful tools to improve peoples' lives, and were honest about what those tools could do, while also carefully weighing the technology's costs. But that's not the world we live in. Instead, we need to push back against endless tech manias and overhyped narratives, and oppose the "innovation at any cost" mindset that has infected the tech sector.
Footnotes
When I refer to "AI" in this piece, I'm mostly referring to the much narrower field of generative artificial intelligence and large language models (LLMs), which is what people generally mean these days when they say "AI". ↩
While much fun has been made of those describing themselves as "prompt engineers", I have to say I kind of get it. It takes some experience to be able to open up a ChatGPT window or other LLM interface and actually provide instructions that will produce useful output. I've heard this compared to "google-fu" in the early days of Google, when the search engine was much worse at interpreting natural language queries, and I think that's rather apt. ↩
ChatGPT was publicly released in November 2022, right as the cryptocurrency industry was in peak meltdown. ↩
Many of which are built with various other kinds of machine learning or artificial intelligence, if not necessarily generative AI. ↩
As it happens, he has also written about the "AI isn't useful" criticism. ↩
Some AI boosters will argue that most or all original thought is also merely a mashup of other peoples' thoughts, which I think is a rather insulting minimization of human ingenuity. ↩
Nor do I want to, by the way. I performed these tests for the purposes of illustration, but I neither intend nor want to start using these tools to replace my writing. I'm here to write, and you're here to read my writing, and that's how it will remain. See my about page. ↩
Something that is absolutely encouraged by the tools' creators, who give them chat-like interfaces, animations suggesting that the tool is "typing" messages back to you, and a confident writing style that encourages people to envision the software as another thinking human being. ↩
Or, more accurately, by managers and executives who believe the marketing hype out of AI companies that proclaim that their tools can replace workers, without seeming to understand at all what those workers do. ↩